Our Mission
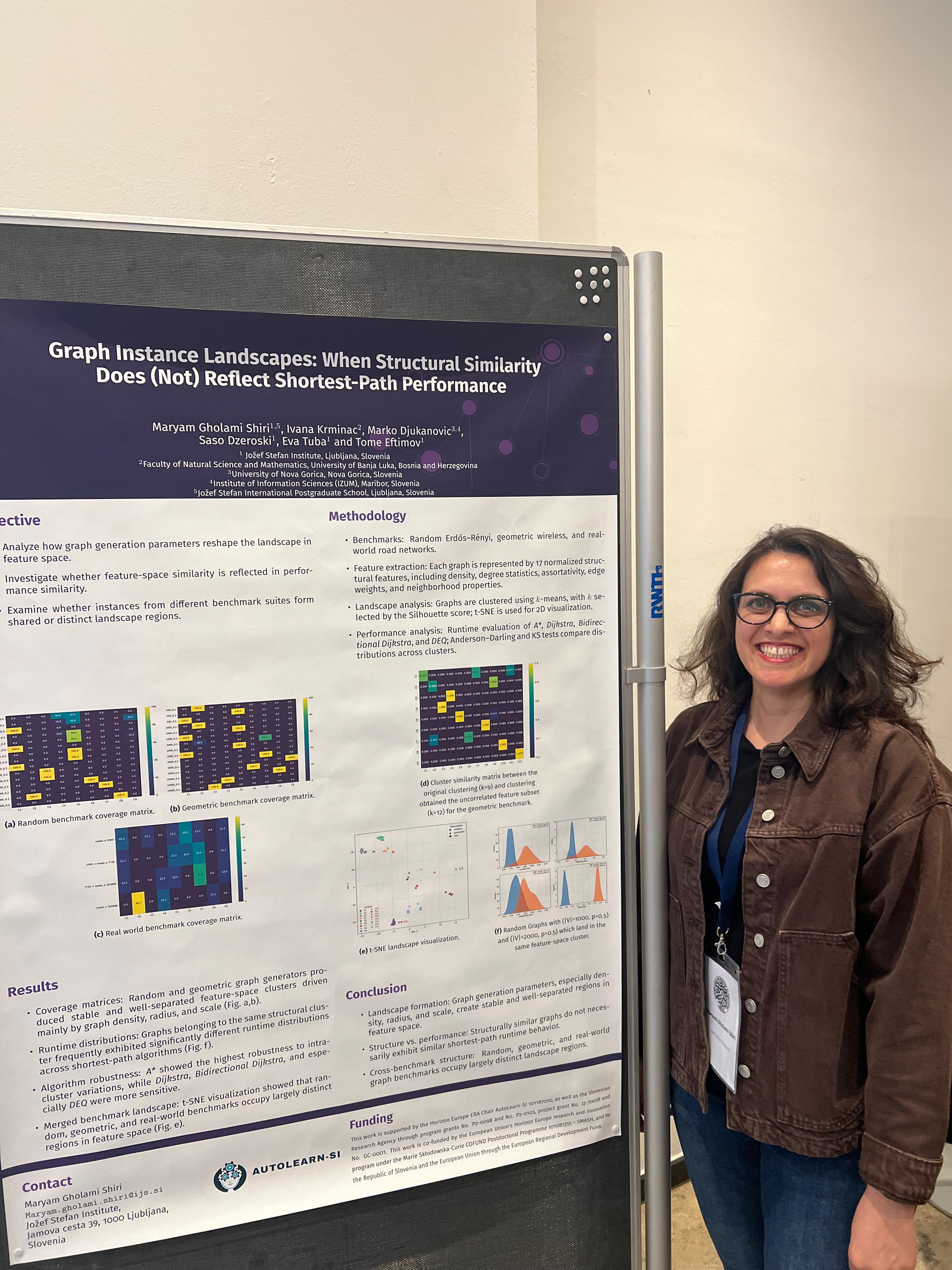
The DATA-TRUST project aims to increase trust in artificial intelligence (AI) systems by developing a framework for smart-sized benchmarking, enabling AI models to generalize better to unseen data.
Instead of relying on very large datasets that may contain redundant or biased information, the project investigates how to select representative subsets of data that preserve diversity and capture the essential characteristics of learning problems.
The project focuses on three key research directions:
Unified representations of benchmark data for different AI domains.

Selection of representative benchmark instances using clustering and graph-based approaches.

Indicators of model generalization that quantify how well AI models perform on unseen data.

The framework will be validated across two domains:
Single-objective Optimization

Time-series analysis

Through these developments, DATA-TRUST contributes to building more reliable, interpretable, and trustworthy AI systems.
The project is funded by the Slovenian Research and Innovation Agency (ARIS) and carried out at the Jožef Stefan Institute (JSI).